昆侖萬維開源2千億稀疏大模型天工MoE,全球首創能用4090推理
2024年6月3日,昆侖萬維宣布開源 2 千億稀疏大模型 Skywork-MoE , 性能強勁, 同時推理成本更低。Skywork-MoE 基于之前昆侖萬維開源的 Skywork-13B 模型中間 checkpoint 擴展而來,是首個完整將 MoE Upcycling 技術應用并落地的開源千億 MoE大模型,也是首個支持用單臺 4090 服務器推理的開源千億 MoE大模型。
開源地址:
Skywork-MoE 的模型權重、技術報告完全開源,免費商用,無需申請:
? 模型權重下載:
? https://huggingface.co/Skywork/Skywork-MoE-base
? https://huggingface.co/Skywork/Skywork-MoE-Base-FP8
? 模型開源倉庫:https://github.com/SkyworkAI/Skywork-MoE
? 模型技術報告:https://github.com/SkyworkAI/Skywork-MoE/blob/main/skywork-moe-tech-report.pdf
? 模型推理代碼:(支持 8x4090 服務器上 8 bit 量化加載推理) https://github.com/SkyworkAI/vllm
模型架構:
本次開源的 Skywork-MoE 模型隸屬于天工 3.0 的研發模型系列,是其中的中檔大小模型(Skywork-MoE-Medium),模型的總參數量為 146B,激活參數量 22B,共有 16 個 Expert,每個 Expert 大小為 13B,每次激活其中的 2 個 Expert。
天工 3.0 還訓練了 75B (Skywork-MoE-Small) 和 400B (Skywork-MoE-Large)兩檔 MoE 模型,并不在此次開源之列。
模型能力:
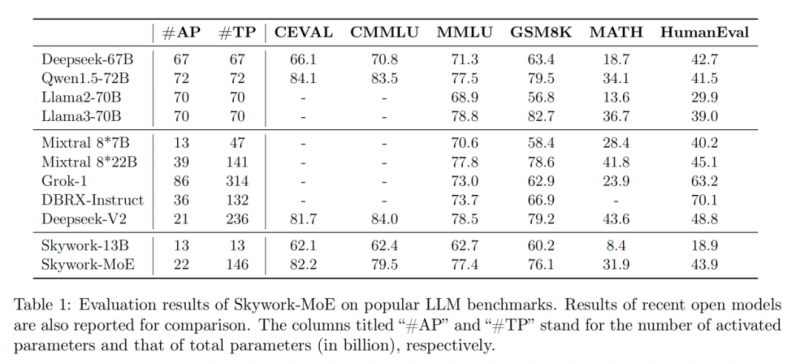
我們基于目前各大主流模型評測榜單評測了 Skywork-MoE,在相同的激活參數量 20B(推理計算量)下,Skywork-MoE 能力在行業前列,接近 70B 的 Dense 模型。使得模型的推理成本有近 3 倍的下降。同時 Skywork-MoE 的總參數大小比 DeepSeekV2 的總參數大小要小 1/3,用更小的參數規模做到了相近的能力。
技術創新:
為了解決 MoE 模型訓練困難,泛化性能差的問題,相較于 Mixtral-MoE, Skywork-MoE 設計了兩種訓練優化算法:
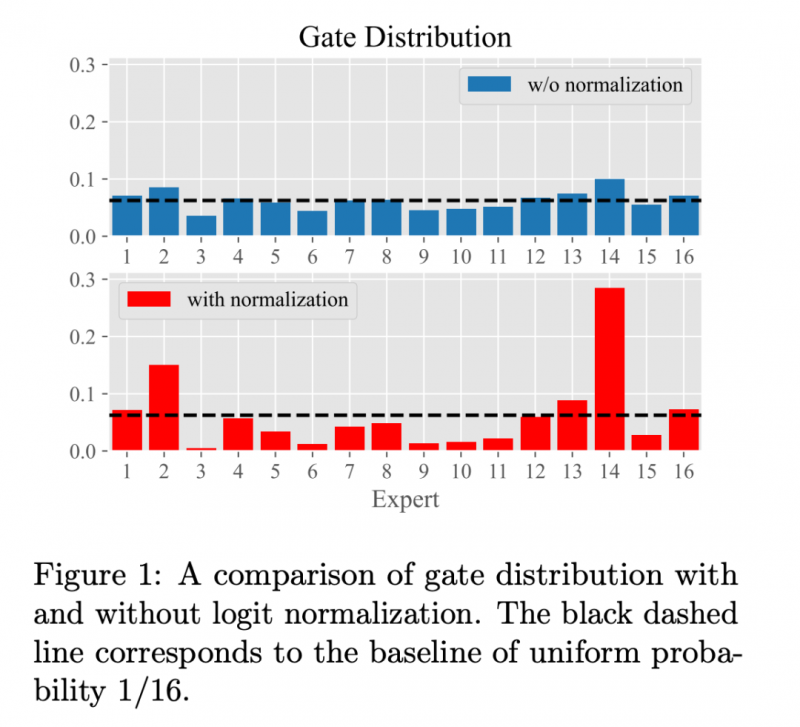
1. Gating Logits 歸一化操作
我們在 Gating Layer 的 token 分發邏輯處新增了一個 normalization 操作,使得 Gating Layer 的參數學習更加趨向于被選中的 top-2 experts,增加 MoE 模型對于 top-2 的置信度:
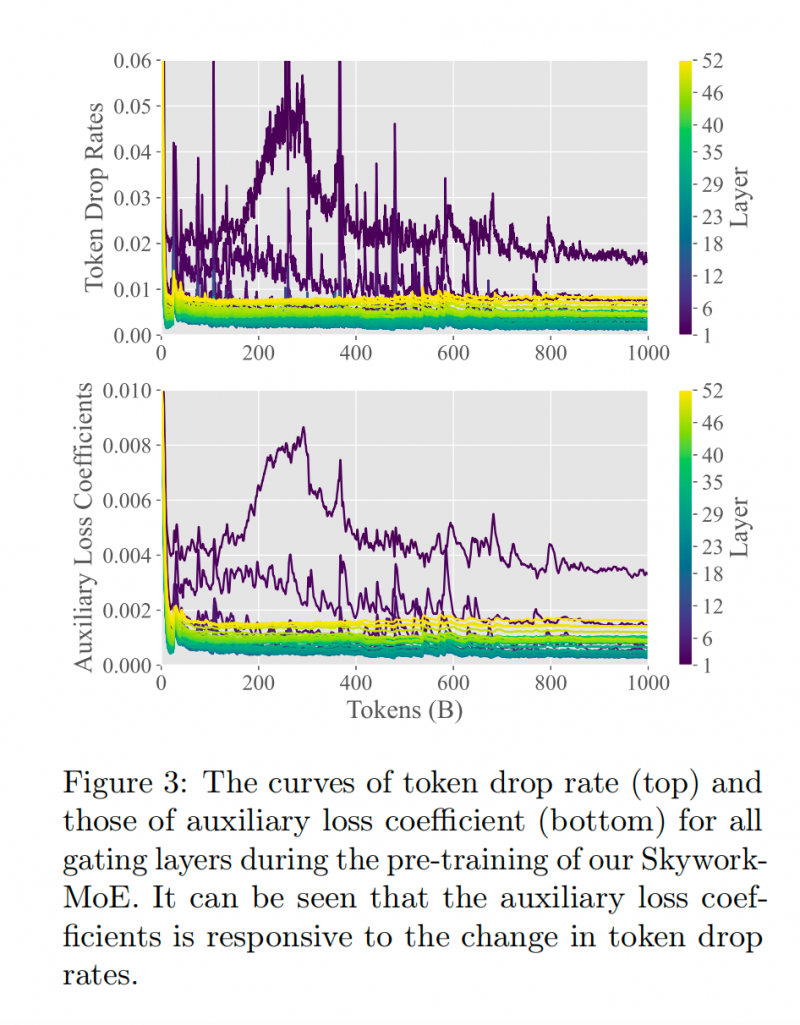
2. 自適應的 Aux Loss
有別于傳統的固定系數(固定超參)的 aux loss, 我們在 MoE 訓練的不同階段讓模型自適應的選擇合適的 aux loss 超參系數,從而讓 Drop Token Rate 保持在合適的區間內,既能做到 expert 分發的平衡,又能讓 expert 學習具備差異化,從而提升模型整體的性能和泛化水平。在 MoE 訓練的前期,由于參數學習不到位,導致 Drop Token Rate 太高(token 分布差異太大),此時需要較大的 aux loss 幫助 token load balance;在 MoE 訓練的后期,我們希望 Expert 之間仍保證一定的區分度,避免 Gating 傾向為隨機分發 Token,因此需要較低的 aux loss 降低糾偏。
訓練 Infra
如何對 MoE 模型高效的進行大規模分布式訓練是一個有難度的挑戰,目前社區還沒有一個最佳實踐。Skywork-MoE 提出了兩個重要的并行優化設計,從而在千卡集群上實現了 MFU 38% 的訓練吞吐,其中 MFU 以 22B 的激活參數計算理論計算量。
1. Expert Data Parallel
區別于 Megatron-LM 社區已有的 EP(Expert Parallel)和 ETP(Expert Tensor Parallel)設計,我們提出了一種稱之為 Expert Data Parallel 的并行設計方案,這種并行方案可以在 Expert 數量較小時仍能高效的切分模型,對 Expert 引入的 all2all 通信也可以最大程度的優化和掩蓋。相較于 EP 對 GPU 數量的限制和 ETP 在千卡集群上的低效, EDP 可以較好的解決大規模分布式訓練 MoE 的并行痛點,同時 EDP 的設計簡單、魯棒、易擴展,可以較快的實現和驗證。
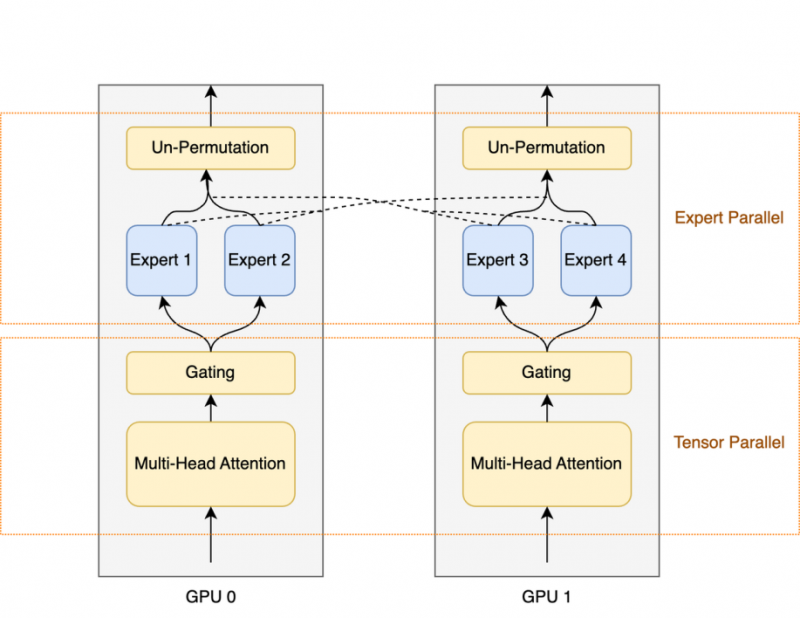
一個最簡單的 EDP 的例子,兩卡情況下 TP = 2, EP = 2, 其中 Attention 部分采用 Tensor Parallel , Expert 部分采用 Expert Parallel
2. 非均勻切分流水并行
由于 first stage 的 Embedding 計算和 last stage 的 Loss 計算,以及 Pipeline Buffer 的存在, 流水并行下均勻切分 Layer 時的各 stage 計算負載和顯存負載均有較明顯的不均衡情況。我們提出了非均勻的流水并行切分和重計算 Layer 分配方式,使得總體的計算/顯存負載更均衡,約有 10% 左右的端到端訓練吞吐提升。
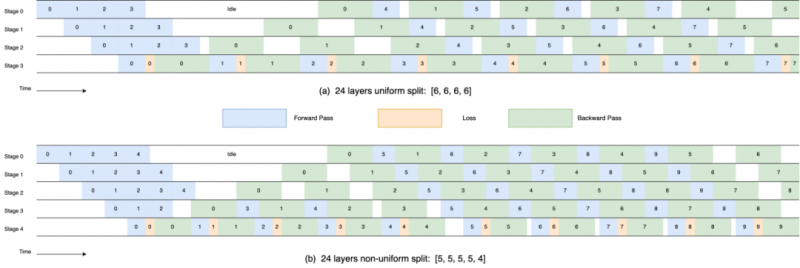
比較均勻切分和非均勻切分下的流水并行氣泡:對于一個 24 層 Layer 的 LLM, (a) 是均勻切分成 4 個 stage,每個 stage 的 layer 數量是:[6, 6, 6, 6].(b) 是經過優化后的非均勻切分方式,切成 5 個 stage, 每個 stage 的 layer 數量是:[5, 5, 5, 5, 4] , 在中間流水打滿的階段,非均勻切分的氣泡更低。
MoE Know-how
此外,Skywork-MoE 還通過一系列基于 Scaling Laws 的實驗,探究哪些約束會影響 Upcycling 和 From Scratch 訓練 MoE 模型的好壞。

一個可以遵循的經驗規則是:如果訓練 MoE 模型的 FLOPs 是訓練 Dense 模型的 2 倍以上,那么選擇 from Scratch 訓練 MoE 會更好,否則的話,選擇 Upcycling 訓練 MoE 可以明顯減少訓練成本。
4090 推理
Skywork-MoE 是目前能在 8x4090 服務器上推理的最大的開源 MoE 模型。8x4090 服務器一共有 192GB 的 GPU 顯存,在 FP8 量化下(weight 占用 146GB),使用我們首創的非均勻 Tensor Parallel 并行推理方式,Skywork-MoE 可以在合適的 batch size 內達到 2200 tokens/s 的吞吐。天工團隊完整開源了相關的推理框架代碼和安裝環境,詳情參見:https://github.com/SkyworkAI/Skywork-MoE
結語
我們希望本次開源的 Skywork-MoE 模型、技術報告和相關的實驗結果可以給開源社區貢獻更多的 MoE 訓練經驗和 Know-how,包括模型結構、超參選擇、訓練技巧、訓練推理加速等各方面, 探索用更低的訓練推理成本訓更大更強的模型,在通往 AGI 的道路上貢獻一點力量。
免責聲明:市場有風險,選擇需謹慎!此文僅供參考,不作買賣依據。
關鍵詞:
- 昆侖萬維開源2千億稀疏大模型天工MoE,全球首創能用4090推理 2024年6月3日,昆侖萬維宣布開源 2 千億稀疏大模型 Skywork-MoE
-
 傳祺M6 MAX正式上市,樹立10-15萬級MPV市場新標桿 傳祺M6自上市以來,便憑借其卓越的產品力和市場口碑,在10-15萬級別
傳祺M6 MAX正式上市,樹立10-15萬級MPV市場新標桿 傳祺M6自上市以來,便憑借其卓越的產品力和市場口碑,在10-15萬級別 -
 安駕有我 暢行魔都 五羊-本田“FUN RIDE DAY”安普中國行 快樂騎行日活動,致力于普
安駕有我 暢行魔都 五羊-本田“FUN RIDE DAY”安普中國行 快樂騎行日活動,致力于普 -
 奧樂齊中國市場再發力,多品類生鮮上新加碼本地化進程 民以食為天,生鮮作為關系民生的重大版塊,歷來備受行業矚目。然而
奧樂齊中國市場再發力,多品類生鮮上新加碼本地化進程 民以食為天,生鮮作為關系民生的重大版塊,歷來備受行業矚目。然而 -
 SUKA酥咔成功入選《品牌中國》欄目,打造國民信賴的體態與健康管理領先品牌! 近日,SUKA酥咔品牌與《品牌中國》欄目達成戰略合作。自創立以來,S
SUKA酥咔成功入選《品牌中國》欄目,打造國民信賴的體態與健康管理領先品牌! 近日,SUKA酥咔品牌與《品牌中國》欄目達成戰略合作。自創立以來,S -
 安駕有我 快樂同行 五羊-本田“FUN RIDE DAY”安普中國行 快樂騎行日活動,致力于普
安駕有我 快樂同行 五羊-本田“FUN RIDE DAY”安普中國行 快樂騎行日活動,致力于普
- 昆侖萬維開源2千億稀疏大模型天工MoE,全球首創能用4090推理 2024年6月3日,昆侖萬維宣布開源 2 千億稀疏大模型 Skywork-MoE
- 傳祺M6 MAX正式上市,樹立10-15萬級MPV市場新標桿 傳祺M6自上市以來,便憑借其卓越的產品力和市場口碑,在10-15萬級別
- 安駕有我 暢行魔都 五羊-本田“FUN RIDE DAY”安普中國行 快樂騎行日活動,致力于普
- 奧樂齊中國市場再發力,多品類生鮮上新加碼本地化進程 民以食為天,生鮮作為關系民生的重大版塊,歷來備受行業矚目。然而
- SUKA酥咔成功入選《品牌中國》欄目,打造國民信賴的體態與健康管理領先品牌! 近日,SUKA酥咔品牌與《品牌中國》欄目達成戰略合作。自創立以來,S
-
以科技金融和風險管控為抓手,哈銀消費金融持續增強市場競爭力! 在金融領域中,“穩健”無疑是一個不可或缺的發展理念。這種穩健不
- 安駕有我 快樂同行 五羊-本田“FUN RIDE DAY”安普中國行 快樂騎行日活動,致力于普
-
 保障高額三者險的必要性! 在現代社會中,交通事故頻發,車輛發展迅猛,道路上的安全問題備受關注。為了保護自己和他人的財產安全,購買高額三者險是一項必要的決策。
保障高額三者險的必要性! 在現代社會中,交通事故頻發,車輛發展迅猛,道路上的安全問題備受關注。為了保護自己和他人的財產安全,購買高額三者險是一項必要的決策。 -
哈銀消費金融七周年:創新金融服務,助力消費金融行業高質量發展 金融企業步入發展“新階段”之際,如何規劃未來,中央金融工作會議
-
新城控股再度成功發行13.6億中票,中債增全額擔保 5月17日,民企債券融資支持工具項下新城控股(601155 SH)2024年度第
-
 HUGO BOSS集團與大衛?貝克漢姆達成多年期戰略性設計合作 HUGO BOSS集團今日宣布,集團旗下品牌BOSS與大衛?貝克漢姆(David
HUGO BOSS集團與大衛?貝克漢姆達成多年期戰略性設計合作 HUGO BOSS集團今日宣布,集團旗下品牌BOSS與大衛?貝克漢姆(David -
 數字化轉型與新基建——白惠源的洞見與展望 如何利用數字化技術推動中小企業實現質的飛躍導語:在第十五屆中國中
數字化轉型與新基建——白惠源的洞見與展望 如何利用數字化技術推動中小企業實現質的飛躍導語:在第十五屆中國中 -
 第87屆全國摩托車及配件展示交易會順利舉辦 2024年5月10日,由中國機械國際合作股份有限公司,中國汽車工業配件銷
第87屆全國摩托車及配件展示交易會順利舉辦 2024年5月10日,由中國機械國際合作股份有限公司,中國汽車工業配件銷 -
 四海賓朋齊聚酒都,共同探尋老白干香型品類健康之美 5月11日上午,作為第六屆印象?衡水老白干酒文化節的重磅活動,“探
四海賓朋齊聚酒都,共同探尋老白干香型品類健康之美 5月11日上午,作為第六屆印象?衡水老白干酒文化節的重磅活動,“探 -
 “品牌新力量 品質新生活”——中國品牌日探20周年美妝國貨品牌 第八個“中國品牌日”在即。來自中國經濟網、中國網財經、中國消費
“品牌新力量 品質新生活”——中國品牌日探20周年美妝國貨品牌 第八個“中國品牌日”在即。來自中國經濟網、中國網財經、中國消費 -
 營銷創新塑造“品牌力” 泰康在線《他們說》視頻榮獲2024“金諾獎” 5月9日,由《中國銀行保險報》主辦的金諾·第八屆金融品牌影響力論
營銷創新塑造“品牌力” 泰康在線《他們說》視頻榮獲2024“金諾獎” 5月9日,由《中國銀行保險報》主辦的金諾·第八屆金融品牌影響力論 -
泰康在線:擁抱AI新勢能 構建保險新質生產力 2021年中國保險行業協會發布的首份《保險科技“十四五”發展規劃》
-
 27歲的天線寶寶,又靠什么躋身潮流“明星”行列? 誕生于上世紀90年代末,曾在120多個國家被翻譯成45種語言,廣受全球
27歲的天線寶寶,又靠什么躋身潮流“明星”行列? 誕生于上世紀90年代末,曾在120多個國家被翻譯成45種語言,廣受全球 -
 極狐,篤信“極致”的力量 2024年過去近四分之一,汽車市場的競逐已然變天:高合、恒大汽車迫于
極狐,篤信“極致”的力量 2024年過去近四分之一,汽車市場的競逐已然變天:高合、恒大汽車迫于 -
 北汽藍谷:有能力有底氣行穩致遠 中國新能源汽車產業光明的前景已經成為共識,因而各路資金和投資主體
北汽藍谷:有能力有底氣行穩致遠 中國新能源汽車產業光明的前景已經成為共識,因而各路資金和投資主體 -
 雙線合作共贏未來,北汽藍谷發起新一輪產品攻勢 如今的汽車的生產制造,對ECU、智能化的需求越來越高,汽車行業相關的
雙線合作共贏未來,北汽藍谷發起新一輪產品攻勢 如今的汽車的生產制造,對ECU、智能化的需求越來越高,汽車行業相關的 -
 車企如何“卷”出新高度?北汽極狐用“競爭性增長”解題 搶發新車、“享界”登場、與華為“雙模式”合作更進一步,深度助力華
車企如何“卷”出新高度?北汽極狐用“競爭性增長”解題 搶發新車、“享界”登場、與華為“雙模式”合作更進一步,深度助力華 -
思特威:營收利潤雙增長 XS系列產品開辟第二條增長曲線 4月26日晚,高性能CMOS傳感器芯片設計領先企業思特威(688213 SH)
-
 北汽藍谷發布年報,蓄勢新周期 4月26日,北汽藍谷發布2023年年報及2024年一季報。年報顯示:北汽藍谷
北汽藍谷發布年報,蓄勢新周期 4月26日,北汽藍谷發布2023年年報及2024年一季報。年報顯示:北汽藍谷 -
 發力PHEV市場,瑞浦蘭鈞攜問頂家族全新系列電池亮相北京車展 4月25日,2024北京車展正式開幕。與往年不同的是,今年北京車展上穩
發力PHEV市場,瑞浦蘭鈞攜問頂家族全新系列電池亮相北京車展 4月25日,2024北京車展正式開幕。與往年不同的是,今年北京車展上穩 -
 泰康惠贏人生(智選版)上市,提供長壽時代財富、健康雙重保障 泰康人壽日前推出“泰康惠贏人生(智選版)年金保險(分紅型)”(以下簡
泰康惠贏人生(智選版)上市,提供長壽時代財富、健康雙重保障 泰康人壽日前推出“泰康惠贏人生(智選版)年金保險(分紅型)”(以下簡 -
 網友整活讓周董唱《科目三》,周氏演唱風格狠狠拿捏了! 周末,我在朋友圈偶然聽到了一首熟悉的旋律,那獨特嗓音和曲風,瞬間勾
網友整活讓周董唱《科目三》,周氏演唱風格狠狠拿捏了! 周末,我在朋友圈偶然聽到了一首熟悉的旋律,那獨特嗓音和曲風,瞬間勾 -
 安吉爾戰略升級,以科技之力引領凈水行業全球發展 4月18日,安吉爾在水立方舉辦“凈水科技 全球領先”戰略升級暨空間
安吉爾戰略升級,以科技之力引領凈水行業全球發展 4月18日,安吉爾在水立方舉辦“凈水科技 全球領先”戰略升級暨空間 -
 超長續航超1000公里!國內乘用車最大電量電池系統發布 進入2024年,動力電池技術迭代方向已經愈發清晰。電池規格標準
超長續航超1000公里!國內乘用車最大電量電池系統發布 進入2024年,動力電池技術迭代方向已經愈發清晰。電池規格標準 -
 “遇見最美的你”,美絲琳墨比斯風夏季發型新品發布 4月18日,假發知名品牌美絲琳亮相時尚雜志ELLE攜手抖音電商發布的熱
“遇見最美的你”,美絲琳墨比斯風夏季發型新品發布 4月18日,假發知名品牌美絲琳亮相時尚雜志ELLE攜手抖音電商發布的熱
熱門資訊
- 昆侖萬維開源2千億稀疏大模型天工MoE,全球首創能用4090推理 2024年6月3日,昆侖萬維宣布開源 ...
- 傳祺M6 MAX正式上市,樹立10-15萬級MPV市場新標桿 傳祺M6自上市以來,便憑借其卓越的...
- 安駕有我 暢行魔都 五羊-本田“FUN RIDE DAY”安普...
- 奧樂齊中國市場再發力,多品類生鮮上新加碼本地化進程 民以食為天,生鮮作為關系民生的重...
文章排行
圖片新聞
-
 國慶假期懷柔北部山區的紅葉進入最佳觀賞期 吸引游客前來賞秋景 國慶假期,懷柔北部山區的紅葉進入...
國慶假期懷柔北部山區的紅葉進入最佳觀賞期 吸引游客前來賞秋景 國慶假期,懷柔北部山區的紅葉進入... -
 重磅!四川省科創貸款較年初新增620.35億元 同比增長21.22% 記者日前從中國人民銀行成都分行獲...
重磅!四川省科創貸款較年初新增620.35億元 同比增長21.22% 記者日前從中國人民銀行成都分行獲... -
 252項“全程網辦”!川渝兩地企業登記檔案實現跨區域互查 8月30日,記者從省大數據中心獲悉...
252項“全程網辦”!川渝兩地企業登記檔案實現跨區域互查 8月30日,記者從省大數據中心獲悉... -
 2022年中國國際服務貿易交易會在京舉辦 四川參展企業數量創新高 8月31日至9月5日,主題為服務合作...
2022年中國國際服務貿易交易會在京舉辦 四川參展企業數量創新高 8月31日至9月5日,主題為服務合作...